網(wǎng)友評論()2015.03.10 總第69期 作者:xukkx
導(dǎo)語:要說2015年至2016年間風靡整個圍棋界和人工智能領(lǐng)域的一件大事,,莫過于新科圍棋計算機程序AlphaGo挑戰(zhàn)著名世界冠軍韓籍棋手李世石九段了。從賽前的輿論風向上看,除了部分計算機界專家對AlphaGo的獲勝充滿信心之外,,普遍的看法還是偏向于人類頂尖棋手能夠戰(zhàn)勝圍棋計算機程序,。如李開復(fù)博士曾在知乎表示人工智能若要戰(zhàn)勝李世石,,還需要1至2年時間的磨練,。然而第一天的戰(zhàn)果卻令大部分人大跌眼鏡,,經(jīng)過一場三個半小時的大戰(zhàn),,AlphaGo執(zhí)白中盤戰(zhàn)勝李世石,,令世人震驚。那么,,人工智能經(jīng)過幾十年的發(fā)展,,究竟到了何種地步?真的可以取代人類智能,,達到一個令人類遙不可及的境界了嗎,?本文通過對人工智能歷史的發(fā)展的梳理,對此問題做一個簡單的探討,。

人機圍棋大戰(zhàn)現(xiàn)場
一,、 人工智能的起源與發(fā)展
人工智能,即人類使用計算機對人類智能的模仿,,讓機器“學會”人類在某一領(lǐng)域的專業(yè)技能,。早在公元前384-322年,Aristotle在其著作《工具論》中提出形式邏輯,。Bacon在《新工具》中提出了歸納法,。萊布尼茨(Leibnitz)提出了通用符號和推理計算的概念,這些都是人工智能研究的萌芽,。進入19世紀以來,,數(shù)理邏輯等學科的進展,,為人工智能的誕生奠定了基石。布爾(Boole)創(chuàng)立的布爾代數(shù)與哥德爾(Godel)提出的不完備理論,,以及圖靈(Turing)提出的自動機理論,,為電子計算機的發(fā)明提供了理論基礎(chǔ)。1943年,,McClloch和Pitts提出了MP神經(jīng)網(wǎng)絡(luò)模型,,開創(chuàng)了人工智能中的重要領(lǐng)域——神經(jīng)網(wǎng)絡(luò)的研究,1945年隨著ENIAC電子數(shù)字計算機的誕生,,人工智能得到了不斷的發(fā)展和應(yīng)用,。如今,人工智能已經(jīng)滲入了普通人生活的方方面面,。比如在人們網(wǎng)購的過程中,,網(wǎng)站可以通過用戶瀏覽網(wǎng)頁的習慣來“猜測”其可能感興趣的商品,并推薦給該用戶,,這項技術(shù)就使用到了人工智能中重要領(lǐng)域“機器學習”中的重要方法,。而機器學習中的重要算法——神經(jīng)網(wǎng)絡(luò),則與本文的主角AlphaGo圍棋程序息息相關(guān),。
二,、 為什么圍棋程序是人工智能重大挑戰(zhàn)?
早在人工智能發(fā)展初期的20世紀50年代,,來自IBM工程研究組的Samuel就開發(fā)出了跳棋程序,,具有初步的學習能力,可以在與人對弈的過程中不斷地積累經(jīng)驗,,提高自己的棋藝,。并且在1959年,這個程序戰(zhàn)勝了其設(shè)計者本人,,1962年,,再次擊敗一位州跳棋冠軍。由此可見,,通過機器學習人類的棋類游戲并與人類對弈,,一直是人工智能應(yīng)用中的一個很令人感興趣的話題。早期人工智能學者對于”計算機很快就會戰(zhàn)勝人類“這個話題曾經(jīng)過分地樂觀過,,60年代初,,人工智能創(chuàng)始人Simon等甚至樂觀地預(yù)言:十年內(nèi)數(shù)字計算機將取代人類獲得國際象棋世界冠軍。
然而經(jīng)過深入的研究,,人們卻發(fā)現(xiàn)人工智能所遇到的困難比想象中的多得多,,比如,Samuel的跳棋程序在擊敗州冠軍后無法再前進一步,。而在國際象棋對弈中,,人類棋手可以在每步三分鐘的時間限制中,,通過直覺與理解,在若干個定式中選擇對自己最為有利的下法,。對于優(yōu)秀棋手而言,通??梢酝ㄟ^思考預(yù)測到5步之后的情形,,而對于電腦程序而言,每行走一步卻面臨著平均每顆棋子超過30余種選擇,,合計起來為了預(yù)測5步以后的情形,,需要考慮下法居然多達1015 種可能,計算機每走一步,,則平均每秒需要檢查百萬種可能的走法,,以當時電腦的計算能力而言,走一步棋需要花費三十年時間,??梢娙绻娔X不能通過對棋局的判斷來減少行棋的復(fù)雜度,僅憑蠻力,,程序很難擊敗人類頂尖棋手,。1968年,在得知人工智能研究者John McCarthy和Donald Michie”十年內(nèi)電腦將擊敗國際象棋世界冠軍”的預(yù)言后,,著名國際象棋世界大師David Levy與人工智能學者打下一個非常著名的賭注:沒有電腦國際象棋程序可以在十年內(nèi)擊敗我,。賭金為1250英鎊。在這十年中,,David Levy成功了擊敗了所有電腦挑戰(zhàn)者,,并在1978年9月在一場六局對決中,以4.5比1.5的比分戰(zhàn)勝當時的終極電腦程序Chess 4.7,,從而最終贏得了自己打下的這個賭,。
盡管贏下了賭注,電腦卻在第四局對局中獲得了勝利,,這是計算機程序歷史上第一次擊敗人類國際象棋大師,。為此,David Levy寫道:盡管我在十年前的斷言是正確的,,然而我的機器對手在這十年中,,比我打賭時進步的太多了,從此以后,,再也沒有會令我震驚的事情發(fā)生了(指電腦程序最終擊敗人類特級大師),。那么,這十年中電腦程序在什么方面取得了進展呢,?
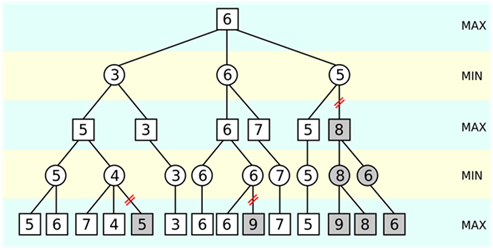
剪枝法示意
轉(zhuǎn)機來源于一種被稱為“剪枝法”的算法被用于象棋程序的估值函數(shù)之中,。估值函數(shù),,即電腦對于當前棋局優(yōu)劣進行判斷的根據(jù),估值函數(shù)根據(jù)當前的局面算得一個分數(shù),,來判斷此棋局是否對自己就有利,,最后,選擇最高得分的那一步作為自己最終的行棋,。如果可選擇的步數(shù)太多,,未經(jīng)過特別的優(yōu)化,則會陷入上文提到的窮舉困境之中,。顧名思義,,“剪枝法”就如同剪掉一棵大樹不重要的“旁枝”一般,去除掉完全不可能的走法,,因故可以減少復(fù)雜度,,對估值函數(shù)最后的選擇起到了優(yōu)化的作用,這么一整套算法被稱為“ alpha-beta 剪枝結(jié)合搜索樹算法”,。
隨著數(shù)十年來算法的不斷改進,,到了七十年代末,國際象棋程序已經(jīng)可以擊敗人類的頂級高手了,。1976年,,在Paul Masson美國國際象棋錦標賽B級的比賽中, Chess4.7的前身,,美國西北大學開發(fā)的Chess4.5擊敗了人類選手,,這是計算機程序首次擊敗人類棋手奪取的人類錦標。到了1982年,,計算機象棋程序每秒可估算1500種不同的走法,,并擊敗絕大部分人類棋手??梢?,程序所取得的進步并非靠計算硬件水平的提高,而是通過算法上的優(yōu)化,,提高程序鑒別“勝負手”的能力和速度,,在一個可行的范圍內(nèi)找出人類棋手的弱點,從而擊潰之,。最著名的“人機”大戰(zhàn)是1997年俄羅斯國際特級大師卡斯帕羅夫與IBM公司研發(fā)的超級計算機深藍(Deep Blue)的對決,,深藍最終的勝出表明人類最強國際象棋特級大師已經(jīng)徹底被人工智能所擊敗,從此再也難以從計算機程序手中拿走一勝了,。
那么既然人工智能算法在國際象棋上已取得了大捷,,基于同樣原理的算法能否在更加復(fù)雜的圍棋中擊敗人類的頂級棋手呢?答案是否定的,,在簡單的規(guī)則下,,標準的19×19棋盤內(nèi),,共有361個點,大概有10170種下法,,而宇宙中已知原子的數(shù)量只有1080個,,可見圍棋棋局之復(fù)雜遠超國際象棋,這也難怪創(chuàng)建高水平的圍棋程序被稱為人工智能領(lǐng)域的重大挑戰(zhàn),。比較而言,,在國際象棋程序中行之有效的“搜索樹”(search tree)算法,在圍棋程序中的推廣卻不甚理想,,難以和職業(yè)圍棋選手抗衡。在AlphaGo出現(xiàn)之前,,基于傳統(tǒng)算法的圍棋程序僅能達到業(yè)余棋手的水平,,遠遠不能令人滿意。而AlphaGo橫空出世后,,首戰(zhàn)即5比0大勝歐洲圍棋冠軍樊麾二段,,展現(xiàn)出不俗的實力。因此,,說AlphaGo的出現(xiàn)嚴重動搖了人類智能在圍棋上的壟斷,,是毫無問題的。那么,,AlphaGo及其研發(fā)的團隊Google DeepMind都有什么亮點呢,?
三、 AlphaGo體現(xiàn)了當今人工智能的最高水平
在談及AlphaGo及其開發(fā)團隊Google DeepMind之前,,必須先簡介一下其領(lǐng)導(dǎo)者哈薩比斯(Demis Hassabis),,可以說,在他出現(xiàn)之前,,幾乎所有研究者都認為在十年內(nèi)人工智能戰(zhàn)勝圍棋大師的機會是渺茫的,。而在他出現(xiàn)以后,幾乎所有人都在驚呼人工智能已破解了圍棋這一歷史難題,,甚至在極短的時間內(nèi)兩次讓研究成果上了《Nature》雜志的封面,。因此,衛(wèi)報(TheGuardian)直呼Hassabis就是人工智能領(lǐng)域的超級英雄,。我認為Hassabis個人完全配得上這個稱謂,。

Hassabis
據(jù)《衛(wèi)報》的報道,Hassabis的終生目標就是開發(fā)出“通用”的人工智能程序,,來解決生活中的一切問題,。他分別取得了劍橋大學和倫敦大學學院的計算機科學和神經(jīng)科學學位。Hassabis稱自己領(lǐng)導(dǎo)的項目就是“21世紀的阿波羅項目”,,這也難怪AlphaGo在擊敗了李世石九段之后Hassabis第一時間在twitter對團隊的祝賀中用“登月”形容圍棋程序擊敗人類頂尖棋手的意義,。而在此之前,,DeepMind通過對近期人工智能技術(shù)中最熱門的一項技術(shù)——深度學習網(wǎng)絡(luò),加上”強化學習”的方法使計算機通過自學的方式在上世紀七八十年代的雅達利經(jīng)典游戲中,,獲得了近乎人類的表現(xiàn),。而這一成果在更早先的時候登上了《Nature》雜志的封面。擁有千年歷史的古老游戲與三十年前的像素游戲紛紛被人工智能攻破,,恐怕在未來若干年間,,人工智能在任何游戲中都強于人類也不會是太令人震驚的事情吧。
以上所有人工智能領(lǐng)域的發(fā)展,,都離不開一項技術(shù)在近年來的突破,,那就是深度學習(Deep Learning),深度學習是傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)技術(shù)的再發(fā)展,。何為神經(jīng)網(wǎng)絡(luò),?神經(jīng)網(wǎng)絡(luò)就是人類提出的一套模擬大腦工作方式的計算機算法。人的大腦有100億個神經(jīng)元,,人類對于環(huán)境的感知,,對于未知事物的認知與神經(jīng)元的“可塑性”息息相關(guān),人腦通過對特定的人物或者感興趣的知識進行“建模”,,神經(jīng)元形成相互連接的“神經(jīng)網(wǎng)絡(luò)”,,并通過互聯(lián)神經(jīng)元的連接強度,即突觸權(quán)值來儲存知識,。而所謂人工神經(jīng)網(wǎng)絡(luò),,就是將化簡后人腦的神經(jīng)元模型實現(xiàn)于電子計算機之上,從而得到類似于人腦的功能,,使計算機可以通過“學習”從外界環(huán)境中獲取知識,。最初等的人工神經(jīng)網(wǎng)絡(luò)出現(xiàn)在20世紀50年代末的“感知機”模型,初步展現(xiàn)了人工神經(jīng)網(wǎng)絡(luò)的學習能力,,后來的研究表明感知機模型只能解決很有限的幾類問題,。神經(jīng)網(wǎng)絡(luò)的最新發(fā)展——深度學習方法源于Geoffrey Hinton教授等人三十多年來的不懈努力研究和推廣,自誕生之日起,,即在機器學習領(lǐng)域中大放異彩,,通過深度學習方法訓(xùn)練出來的模型,在某些特別的圖像識別和語音識別的任務(wù)中,,甚至有超過人類的表現(xiàn),。在當下,深度學習方法是最接近人類大腦的人工智能學習算法,。那么將深度學習網(wǎng)絡(luò)應(yīng)用于圍棋程序AlphaGo又與傳統(tǒng)的國際象棋程序深藍有什么區(qū)別呢,?
據(jù)AlphaGo官方博客介紹,AlphaGo采用了一種更加“通用”的人工智能方法,即采用將改進的蒙特卡洛決策樹算法與深度神經(jīng)網(wǎng)絡(luò)算法相結(jié)合的方法構(gòu)建最終的學習系統(tǒng),。其中,,深度神經(jīng)網(wǎng)絡(luò)由一個多達12層的包含上百萬個神經(jīng)元節(jié)點的神經(jīng)網(wǎng)絡(luò)構(gòu)成,其包括兩個部分:策略網(wǎng)絡(luò)與價值網(wǎng)絡(luò),。具體的技術(shù)細節(jié)在此不贅言,,僅說說其發(fā)揮的作用。策略網(wǎng)絡(luò)在當前給定的棋局中,,負責預(yù)測下一步的走棋,,并對下一步走棋的好壞進行打分,如果是好棋,,就打高分,,最終,最高分的走法被策略網(wǎng)絡(luò)選為下一步棋的走法,。而這個最高分如要如何評定呢,?此時,現(xiàn)存于人類數(shù)據(jù)庫中的圍棋棋譜的作用就體現(xiàn)出來了,,對比以往高手對決的棋譜,如果如此走法能得到最終的勝利,,那就是好棋,,這步就可以評高分,因為以往棋譜的勝負是已知的,,反之亦然,。在這里,人類歷史上的大量圍棋起了訓(xùn)練數(shù)據(jù)的作用,,好比老師在“監(jiān)督”學生做練習,,答對了就給高分,答錯了不給分,。通過對于三千萬步人類棋譜的學習,,AlphaGo對于人類棋手下一步走棋的預(yù)測準確率高達57%(之前為43%)。策略網(wǎng)絡(luò)的作用好比“模仿”人類棋手的各種走法,,以達到預(yù)測的效果,。
然而僅憑模仿無法擊敗最頂級的人類高手。因此,,AlphaGo增加了價值網(wǎng)絡(luò)來判斷當前的局面,,到底對哪一方有利,這一步類似于國際象棋程序中的估值函數(shù),,而具體的實現(xiàn)方法卻有所不同,,象棋程序中需要人工調(diào)整估值函數(shù)中的權(quán)重,以達到最好的效果,甚至需要水平極高的國際特級大師參與調(diào)整參數(shù),。而圍棋程序的局勢評估相當困難,,只能通過深度學習網(wǎng)絡(luò)之間自我訓(xùn)練的方法來達到良好的效果。與國際象棋程序相比,,圍棋好比人類用自己的知識訓(xùn)練電腦,,使其達到人類高手的水平,而國際象棋程序則是人類親自將行棋的方法與邏輯設(shè)計為電腦程序,,最終由計算機代表人類與人類高手進行對弈,。根據(jù)Facebook人工智能組研究員田淵棟博士介紹,為了得到合適的價值網(wǎng)絡(luò)模型,,AlphaGo通過自我對局三千萬盤的方式訓(xùn)練得到了強有力的價值網(wǎng)絡(luò)模型,,最后再通過傳統(tǒng)的蒙特卡洛搜索樹方法結(jié)合以上兩種深度神經(jīng)網(wǎng)絡(luò)模型,最終得到了完整的AlphaGo圍棋程序,??梢哉fAlphaGo的研發(fā)是當今人工智能領(lǐng)域各類技術(shù)的集大成者,體現(xiàn)了人工智能技術(shù)的最高水平,。
四,、 人工智能超越人類還要多久?
李世石在圍棋人機大戰(zhàn)第一盤中的失利,,幾乎掀起了軒然大波,,似乎一夜之間人工智能已經(jīng)戰(zhàn)勝人類智能,甚至人工智能完全超越人類智能的那一天似乎也不會遙遠了,。為此,,需要對“人工智能”的概念做一個簡單的澄清。
對于人工智能的看法,,一直分兩派不同的觀點,,一派是強人工智能,即通過不斷地發(fā)展機器終將獲得類人的自我意識,,最終通過不斷地自我進化獲得遠強于人類的智能水平,。而另一派則認為人工智能只是對人類勞動的接管,僅在部分領(lǐng)域超越人類,,全面超越人類智能只是一個夢想而已,。
從目前的研究現(xiàn)狀看,強人工智能的研究幾乎陷入了停滯,,遠超過人類智能的強人工智能是否存在依然是個很有爭議的話題,,更不要說具體的研究方向了。而主流的機器學習技術(shù),,依然集中于對人類技能的學習,,并通過學習的成果來解決實際的問題。比如說圍棋程序AlphaGo,盡管比起國際象棋機器深藍進步很大,,然而本質(zhì)上依然是在給定規(guī)則具體游戲上的探究,,一旦改變了規(guī)則,甚至換不同規(guī)格的棋盤,,AlphaGo就必須推倒重來,,重新搜集相應(yīng)棋譜來獲得棋力了。很明顯,,這和人類所認識的“舉一反三”類型的“創(chuàng)造知識”的智慧是不相符的,。如果要問當今的人工智能是否達到了三歲小孩的智力水平,那也是一件無法比較的事情,,因為通過不斷地訓(xùn)練機器可以在特定技能上完勝小孩子,,但是在一些看似簡單的學習上,小孩子需要花費的精力卻遠小于機器,。比如拿起桌子上的杯子喝水,,對于小孩來說很容易學會,對于智能機器來說,,卻是件連問題是什么都很難描述清楚的事情,,更不要說自主學習了。因此,,在未來很長一段時間內(nèi),,所謂人工智能,依然只是對人類技能的補充,,好比工具,是對人類智慧的拓寬,,即“機器使用人類的知識戰(zhàn)勝了人類”,,而遠非到了遠超人類智慧的地步。
當然,,人類對于智能的理解還很淺,。就拿上文所提的深度學習舉例,雖然在實用中獲得了廣泛的應(yīng)用,,然而人們對其背后的數(shù)學機制依然不太清楚,,不知道機器做出結(jié)論的依據(jù)是什么,甚至連Hassabis本人也說不清楚AlphaGo的棋力到底幾何,?;蛟S直到人類對“智能是什么”這種問題的本質(zhì)了解透徹之時,對于“人工智能能否超越人類”這個話題才能得到令人滿意的答案吧,。

蘭臺
鳳凰歷史特約記錄員

鳳凰歷史 官方微信
微信掃描二維碼
每天看精彩歷史

所有評論僅代表網(wǎng)友意見,,鳳凰網(wǎng)保持中立